CS224n Lecture 2 Word Vectors,Word Senses, and Classifier Review
1. Review: Main idea of word2vec
如图,中心词预测上下文- Skip-Gram model
- 随机一个词向量开始
- 在整个语料库上迭代每个词
- 试着用中心词预测周围词,如下图
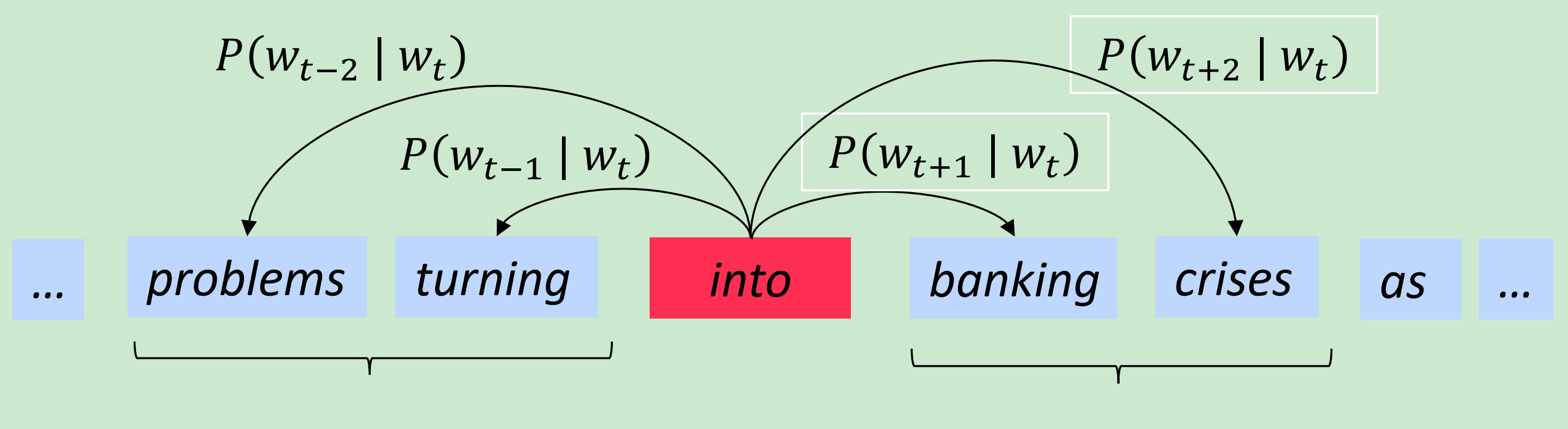
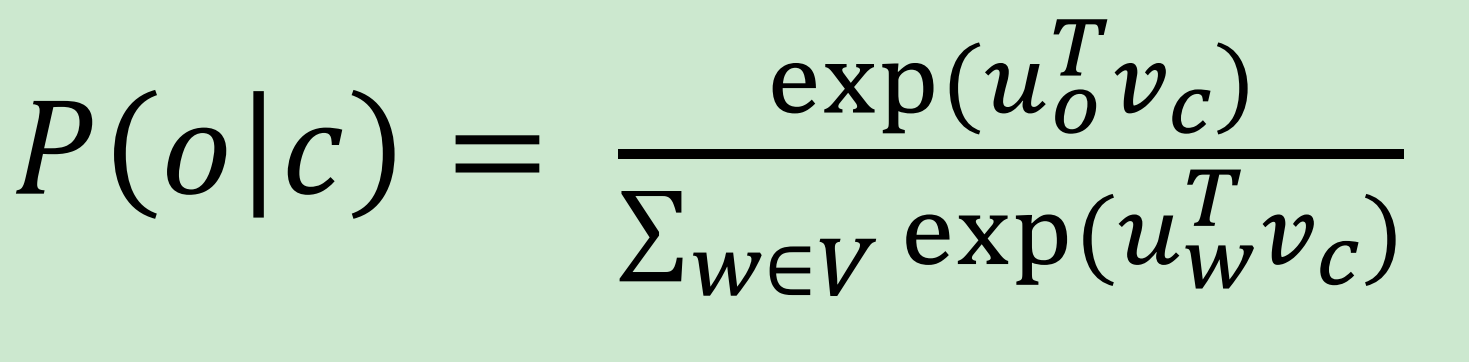
更新向量
- 该算法学习词向量, 在词向量空间上,获得相似性和有意义的方向。U和V是长度为N的向量,需要学习得到。
Word2vec parameters and computations
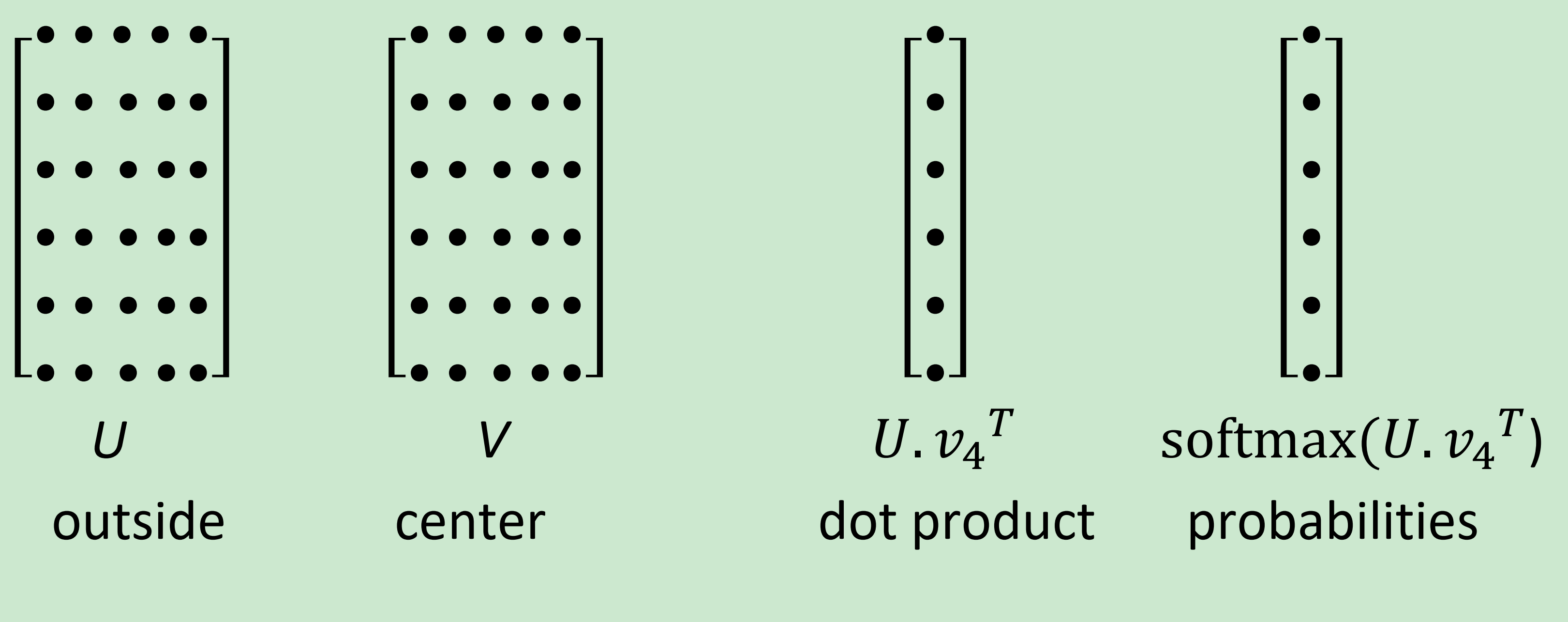
注意:
- 在每个方向上都是一样的预测
- 期望模型对所有出现在上下文(相当频繁)的词给一个合理的高概率值估计
Word2vec maximizes objective function by putting similar words nearby in space

2. Optimization: Gradient Descent
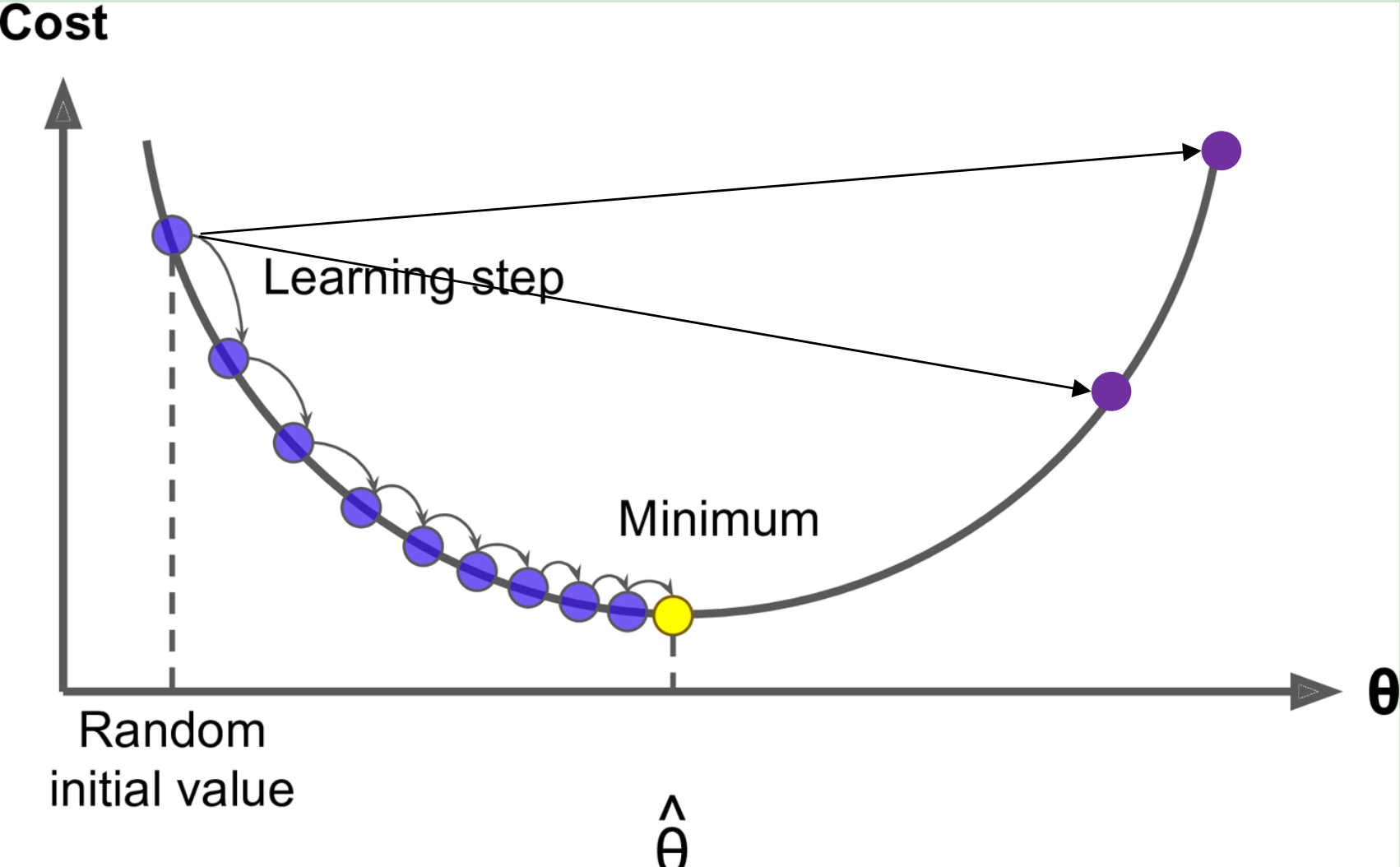
Gradient Descent
更新公式(矩阵形式)
其中是步进或学习率
更新公式 (单一参数)
- 算法

Stochastic Gradient Descent
问题: 是一个在整个语料集上遍历窗口的目标函数,可能上百万规模
- 计算其梯度非常昂贵
- 做单词更新就要非常久。
- 对于大量神经元更不好
措施:
- SGD
- 重复同一窗口,然后更新每个梯度

Stochastic gradients with word vectors!
- 重复地在每个窗口上取梯度进行SGD
- 在每个窗口,只有至多个词,其梯度是十分稀疏的
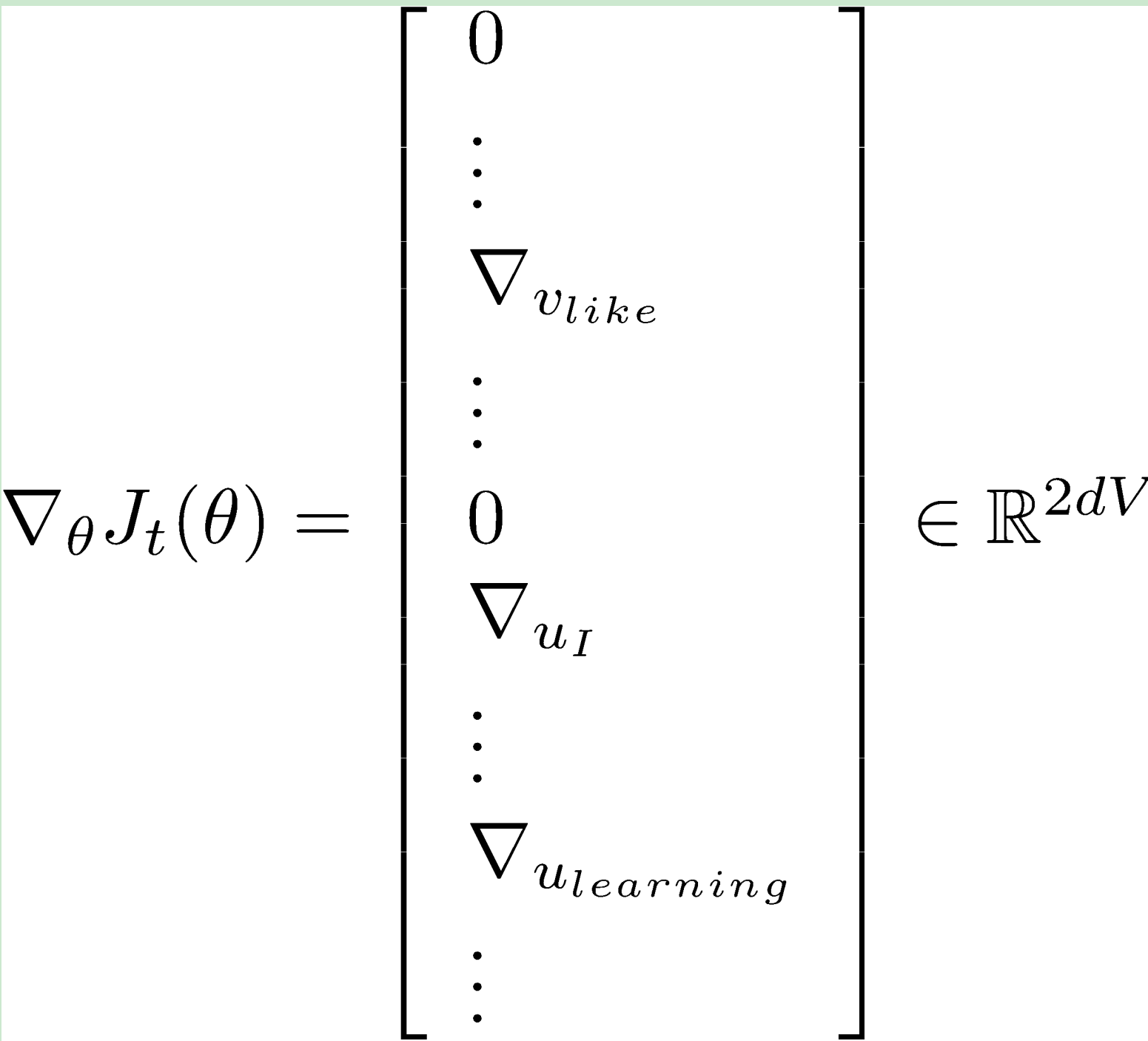
- 可能仅更新实际出现的词向量
- Solution: 要么需要稀疏矩阵更新操作来更新整个嵌入矩阵
U和V的特定行,或者对每个词向量保留周围的哈希值
Word2vec: More details
Two model variants:
Skip-grams (SG): Predict context (“outside”) words (position independent) given center word
Continuous Bag of Words (CBOW):Predict center word from (bag of) context words
The skip-gram model with negative sampling
- 归一化因子计算非常昂贵,指上面图P(o|c)分母。
- 因此,用负采样,用下面两个训练一个二分类logistic regression :
- 真实值:一对中心词和窗口内的上下文
- 随机噪声:一对中心词和随机词
- 从《Distributed Representations of Words and Phrases and their Compositionality 》中,得目标函数为
其中,
- 式4的第一个对数, 最大化两个词的共现概率
- 更像分类的表示
词向量相邻,作为正样本,再选取k个与词c不相邻的词(k一般不超过15)组成k个负样本。目标函数如下:
词向量如果相近,那么会很大,经过sigmoid后会趋于1,大于0但接近0的树。
同理,设词k与词c不相邻,是一个很小的数。
- 词w的词频为, 选择词w作为c的不相邻概率为:
其中,分母Z是归一化因子,使得,所有词被选取概率和为1。
We investigated a number of choices for Pn(w) and found that the unigram distribution U(w) raised to the
3/4rd power (i.e.). U(w)3/4/Z) outperformed significantly the unigram and the uniform distributions, for > > both NCE and NEG on every task we tried including language modeling (not reported here) .——引用自 Distributed Representations of Words and Phrases and their Compositionality
3. Why not capture co-occurrence counts directly?
共现矩阵X
- 实现方法:窗口或者全部文档
- 窗口:类似word2vec, 对每个词用窗口,获取句法和语义信息
- 全部文档共现矩阵将给出普通topics,导致”隐语义分析“
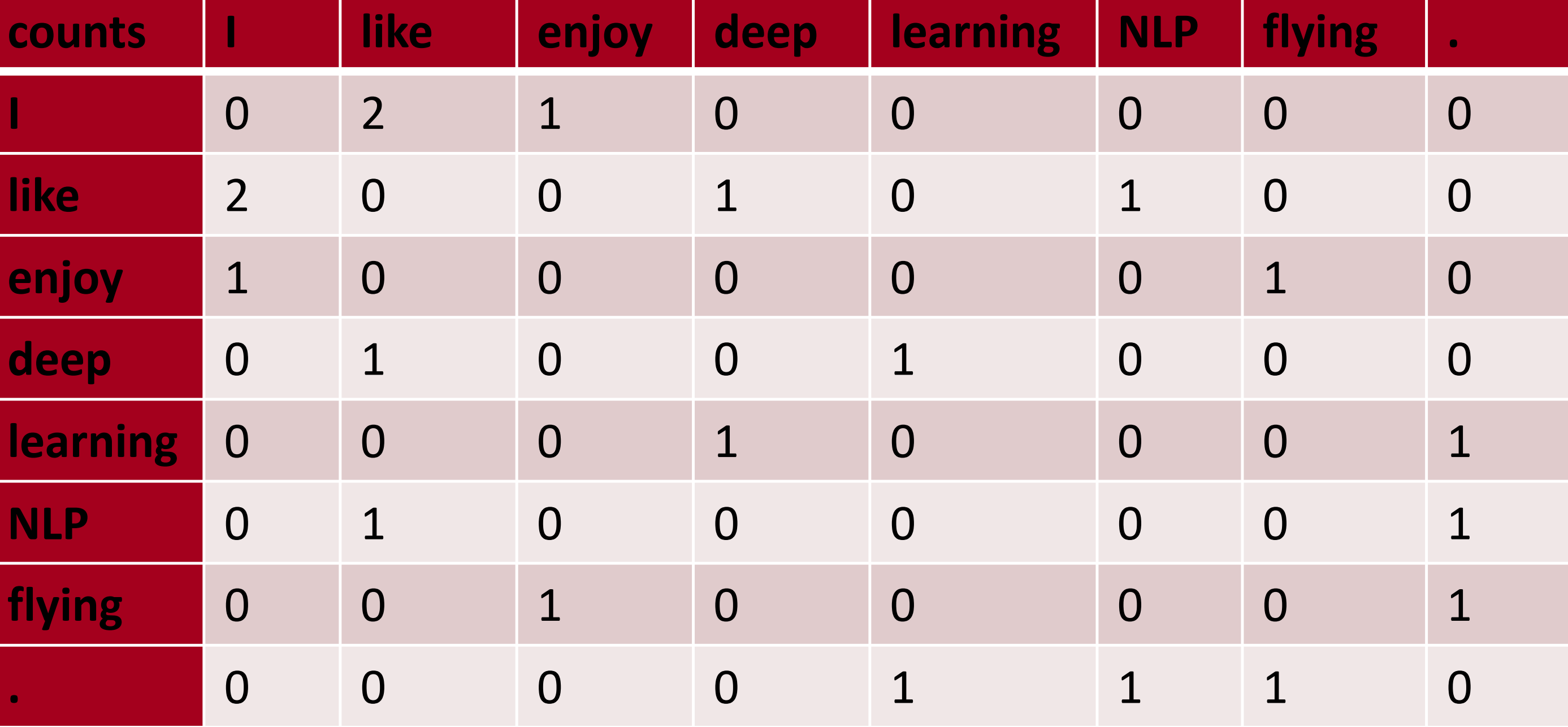
Example: Window based co-occurrence matrix
- 窗口长度1(通常5-10)
- 对称
Problems with simple co-occurrence vectors
- 随词汇表的大小增大,高纬度, 需要更多存储空间
- 子序列分类问题模型有非常稀疏的问题
- 导致模型不鲁棒
Solution: Low dimensional vectors
- 存储大部分重要的信息到, 一个固定的低维度的稠密向量
- 通常25-1000维,类似于word2vec
- 如何降低维度
Method: Dimensionality Reduction on X
奇异值分解,取前k个奇异值,来近似矩阵X,上一篇论文有代码,主要根据奇异值分解的几何意义。介绍SVD
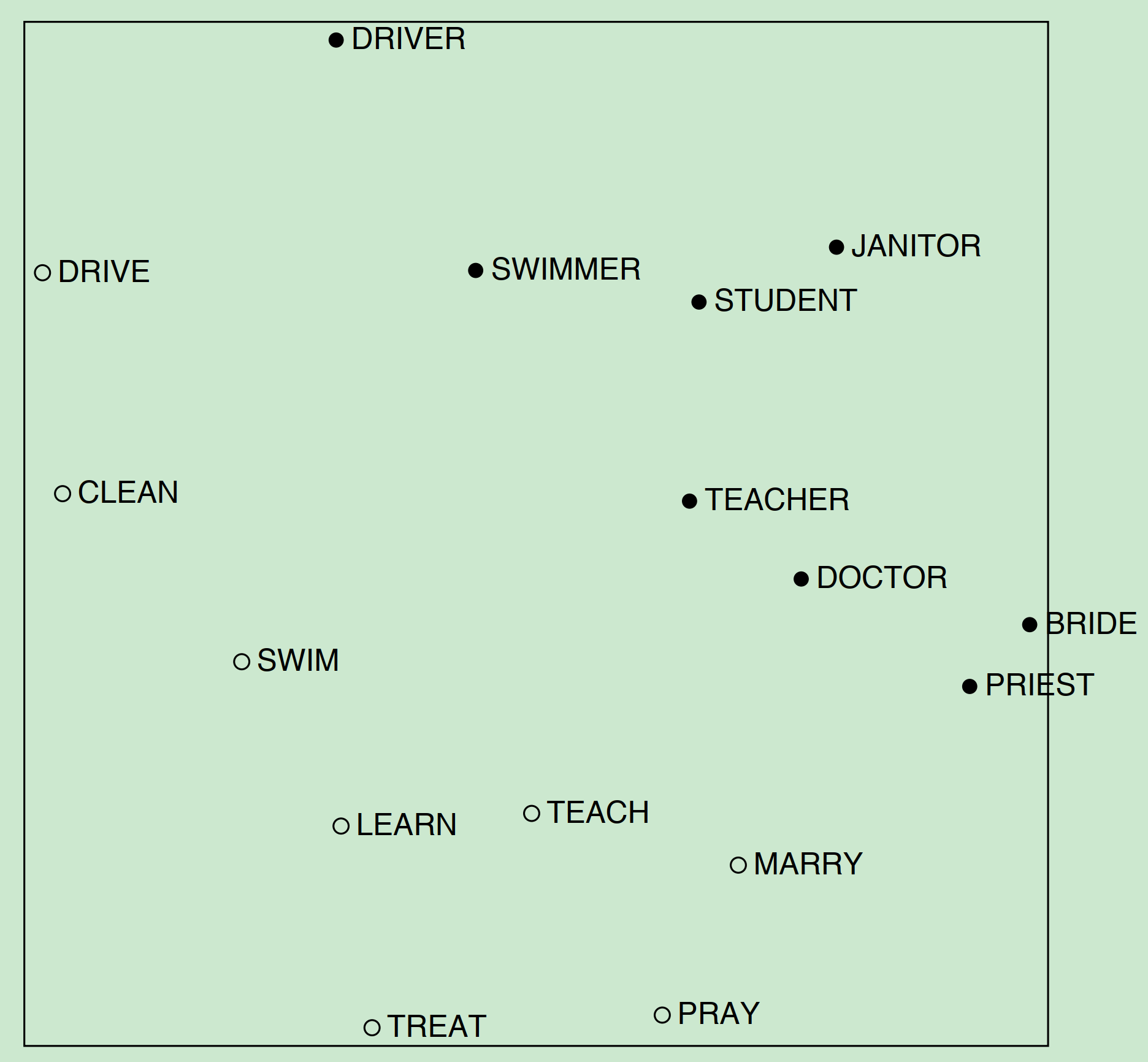
Interesting syntactic patterns emerge in the vectors
4. Towards GloVe: Count based vs. direct prediction
基于计数的算法(LSA,HAL)和直接预测的算法(skip-gram,CBOW)各有各的优点和缺点。
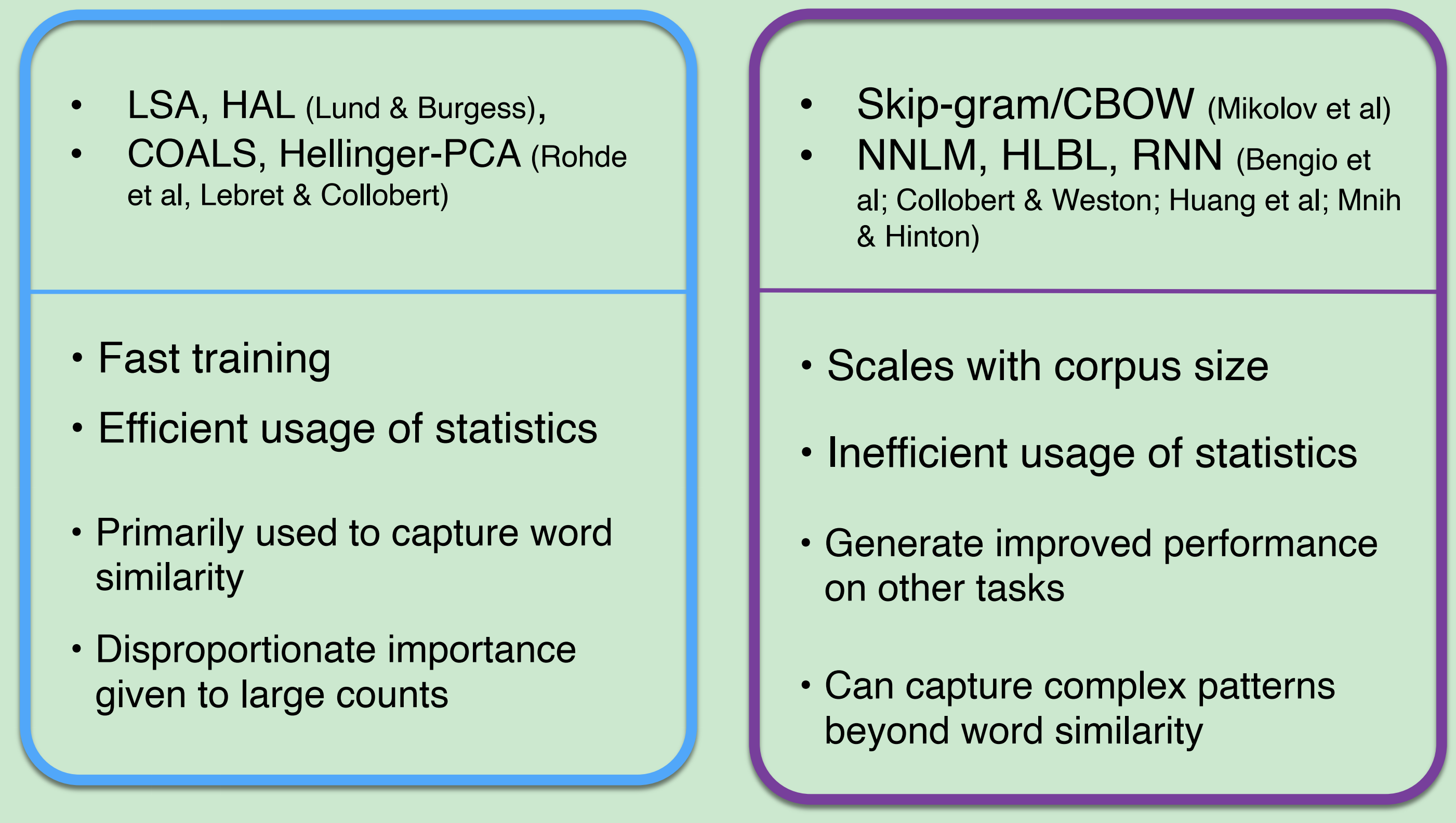
共现概率的比值, 比值可以体现两个词之间的类比关系。

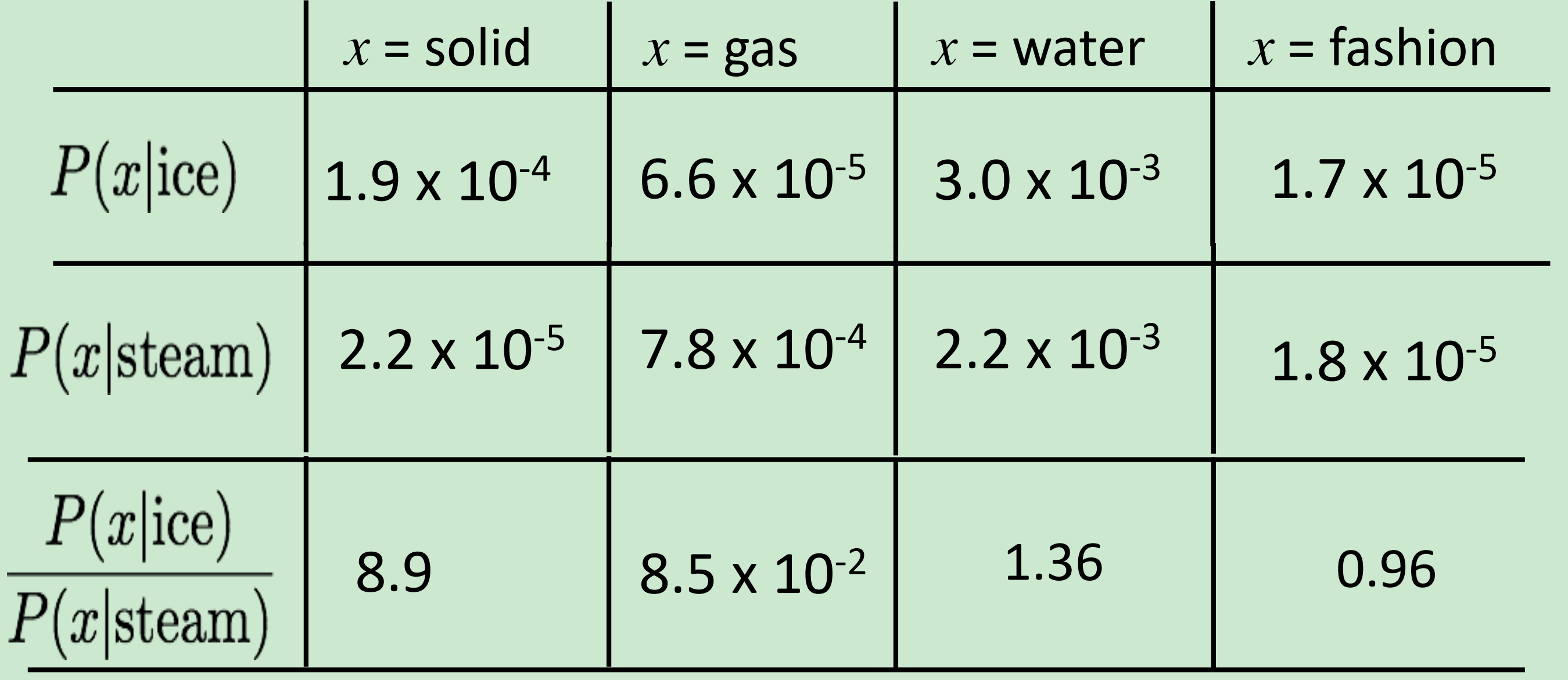
举例说明就是,冰ice和固体soild与蒸汽steam和固体soild比较,因为是8.9所以说明,前者关系更大,也就是冰与蒸汽相比,冰与固体关系更大,或者说越接近。
Encoding meaning in vector differences
Q:How can we capture ratios of co-occurrence probabilities as linear meaning components in a word vector space?
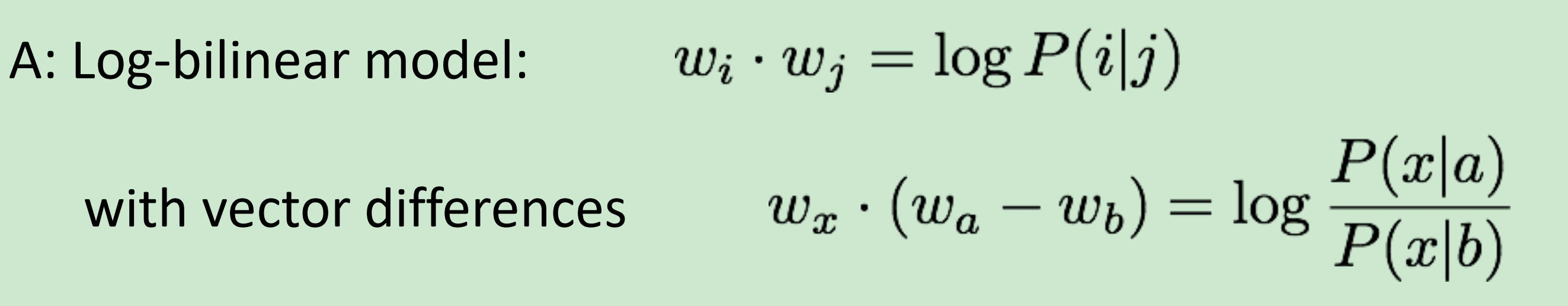
Combining the best of both worlds GloVe [Pennington et al., EMNLP 2014]
Glove每个词只有一个词向量,我们希望词i和词j的词向量可以表示词i在词j周围的概率。
如果对于词x,用如下公式来推断x跟a有关还是b有关。
$w_x \cdot (w_a - w_b) $越大, x与a有关;越小, x与b有关;适中,可能和a,b有关也有可能都无关。
人为指定一个目标函数,在最小化目标函数的过程中学习词向量。
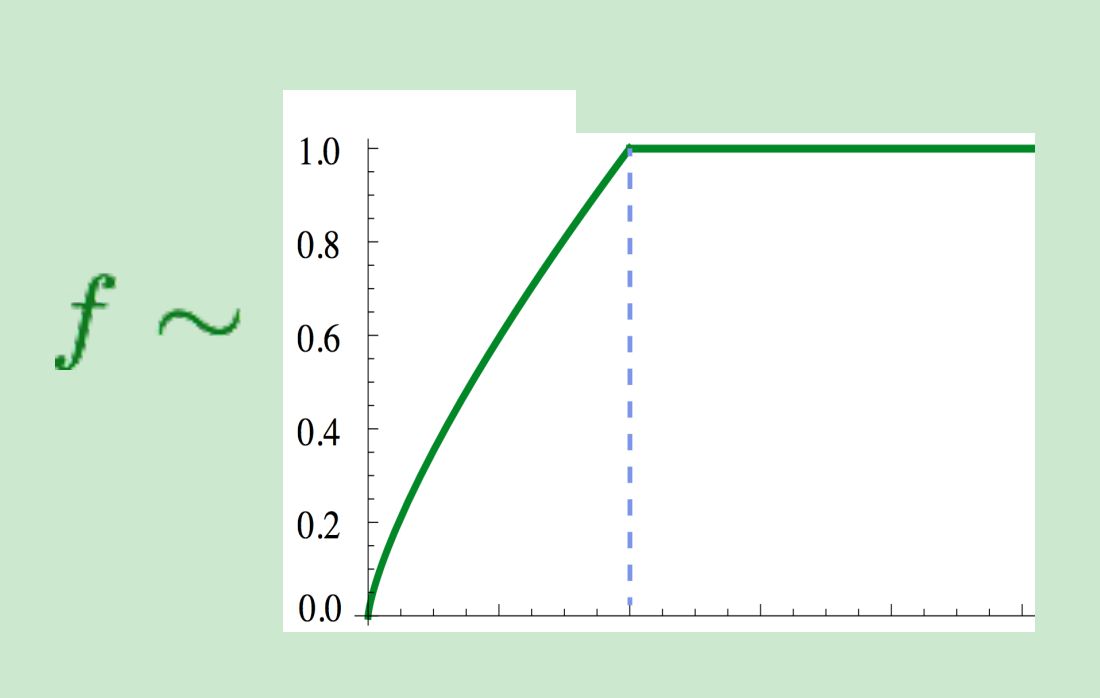
其中, w是词向量,X是共现矩阵,b是偏置。f(x)是一个人为规定的函数,近似为min(t, 100), 作用是降低常见词the””, “a”的重要性。
Golve :
- 快速向量
- 适合当面语料库
- 小语料库和短向量也表示不错
5. How to evaluate word vector
两种方法:
- Intrinsic:专门设计单独的试验,由人工标注词语或句子相似度,与模型结果对比。好处是是计算速度快,但不知道对实际应用有无帮助。有人花了几年时间提高了在某个数据集上的分数,当将其词向量用于真实任务时并没有多少提高效果。
Extrinsic: 通过对外部实际应用的效果提升来体现。耗时较长,不能排除是否是新的词向量与旧系统的某种契合度产生。需要至少两个subsystems同时证明。
Intrinsic word vector evaluation
a:b::c:?, 词向量类比。通过词向量夹角的余弦来推断。
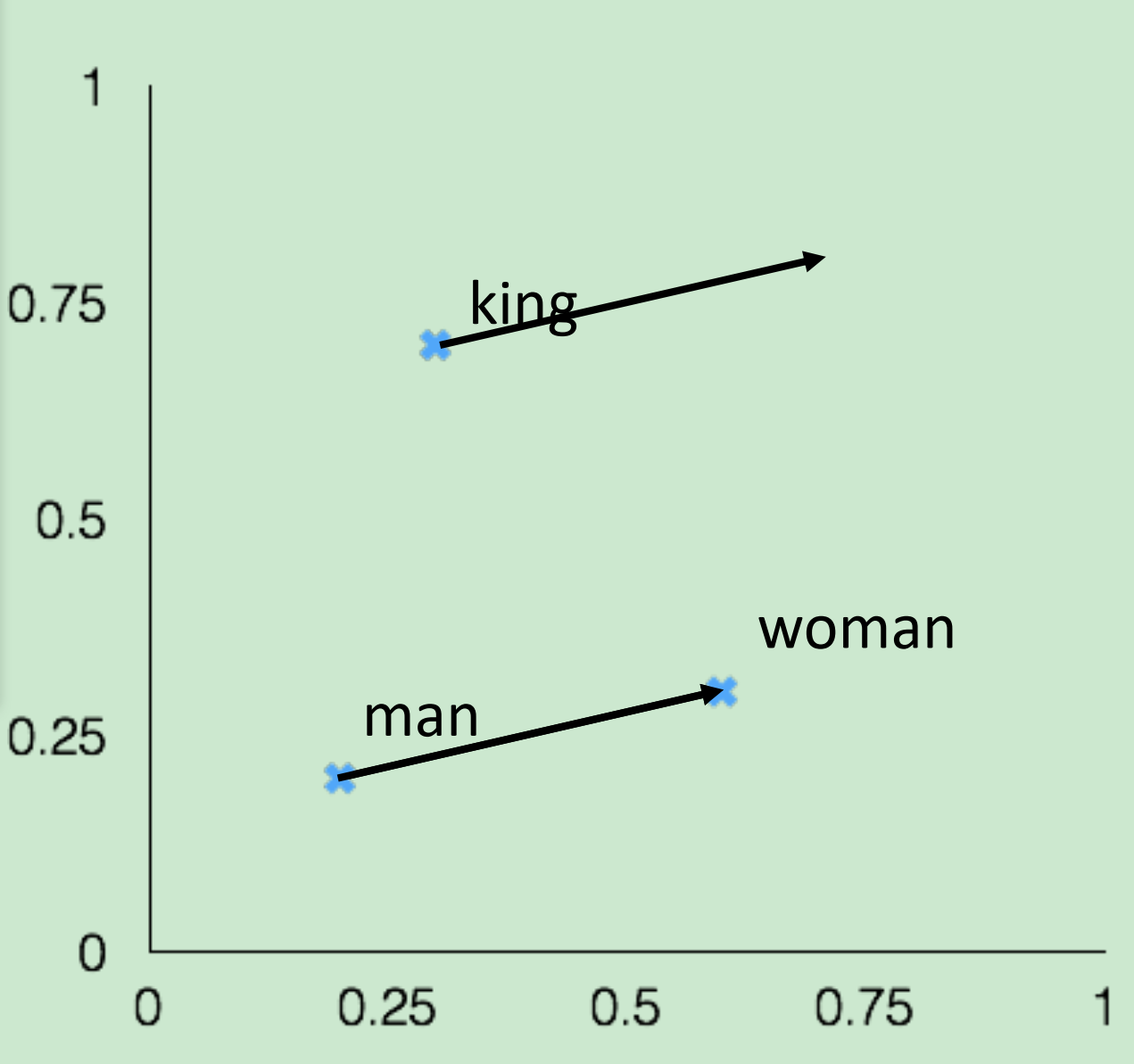
这样的类比在词向量中其实很简单,“woman”词向量减去“man”词向量近似于“king”词向量减去“queen”词向量即可。
Glove Visualizations
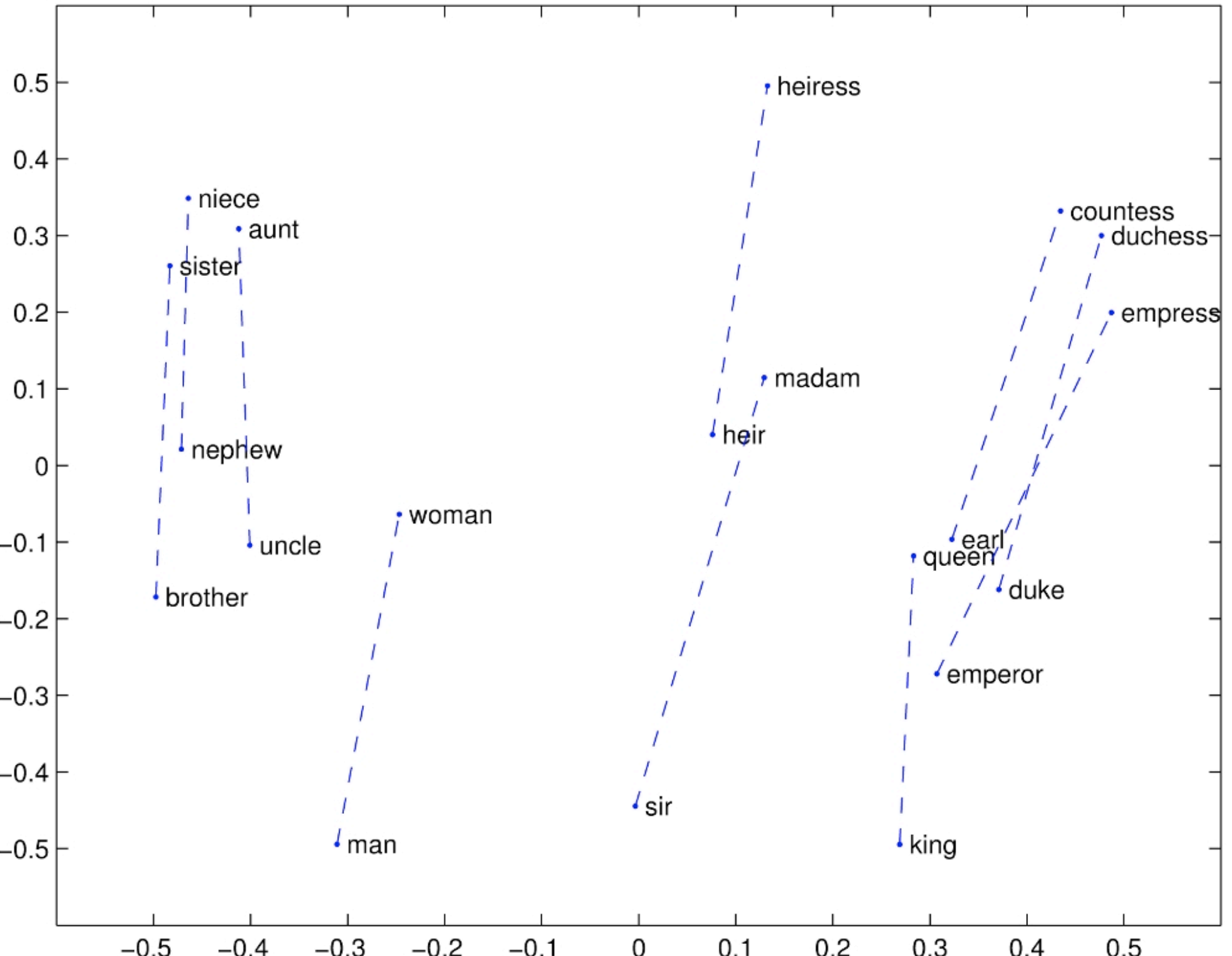
Analogy evaluation and hyperparameters
Glove 词向量估计:
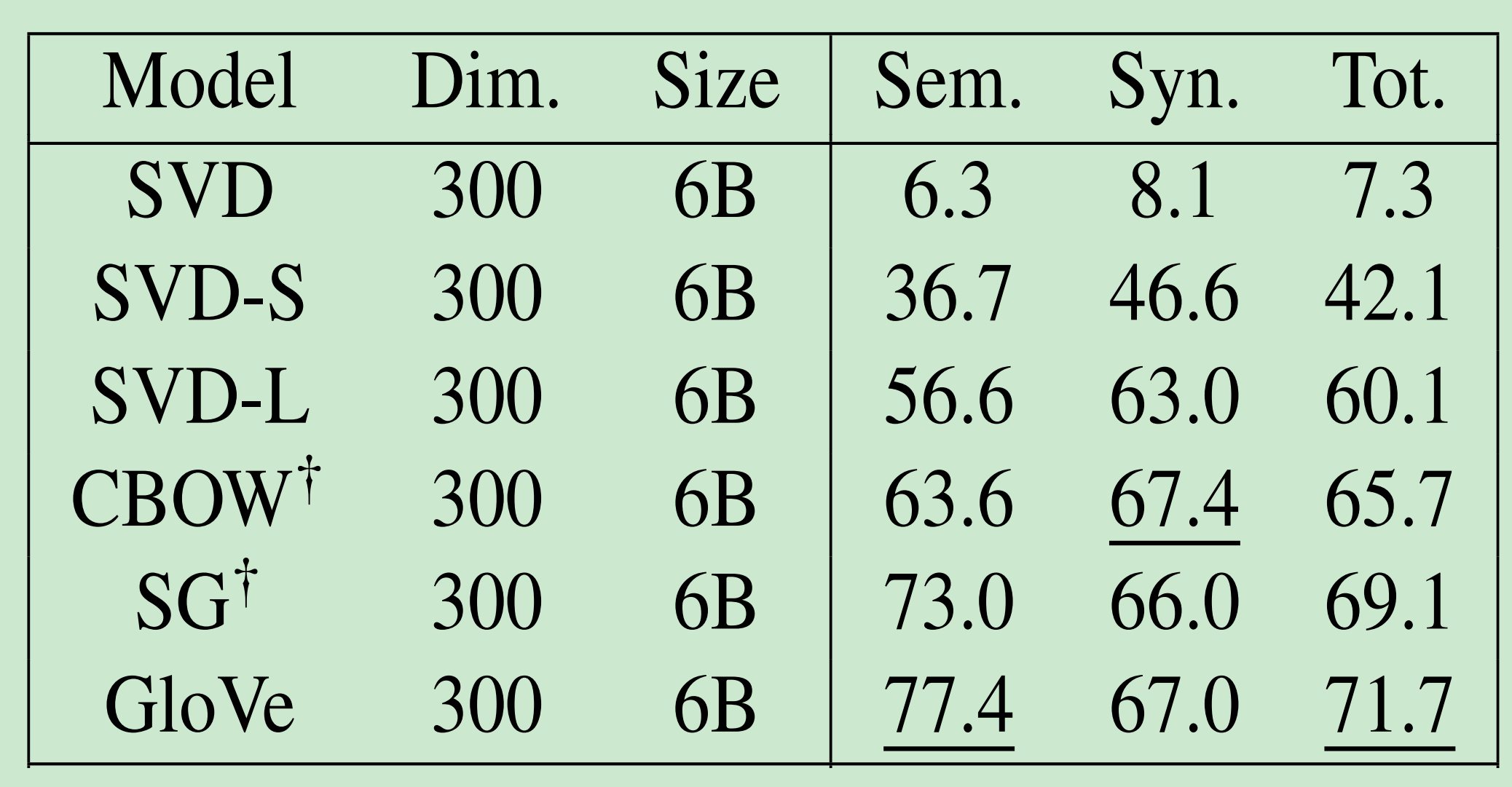
在不同大小的语料上,训练不同维度的词向量,在语义和语法数据集上的结果。
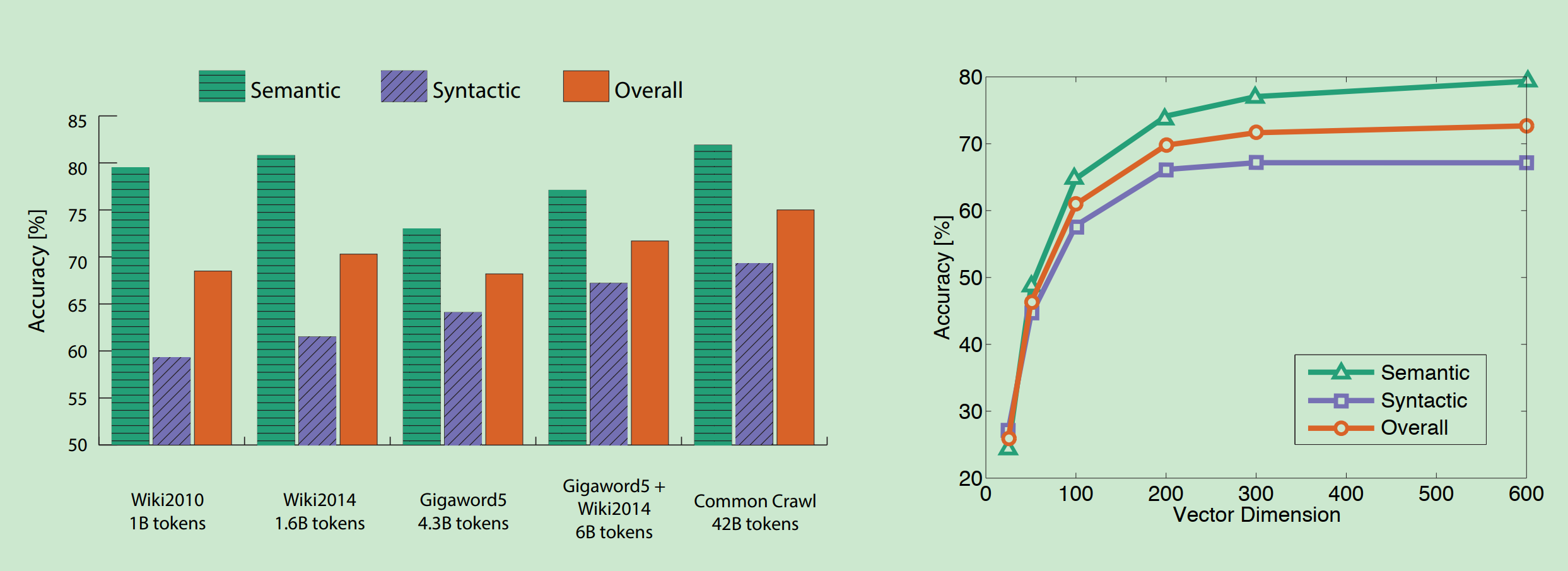
下图显示:
- 更多的数据是有帮助的
- wiki比新闻文本更好
- 维度
- 最合适的维度大约300
另一个内在词向量估计
- 词向量的距离跟人类评判有关
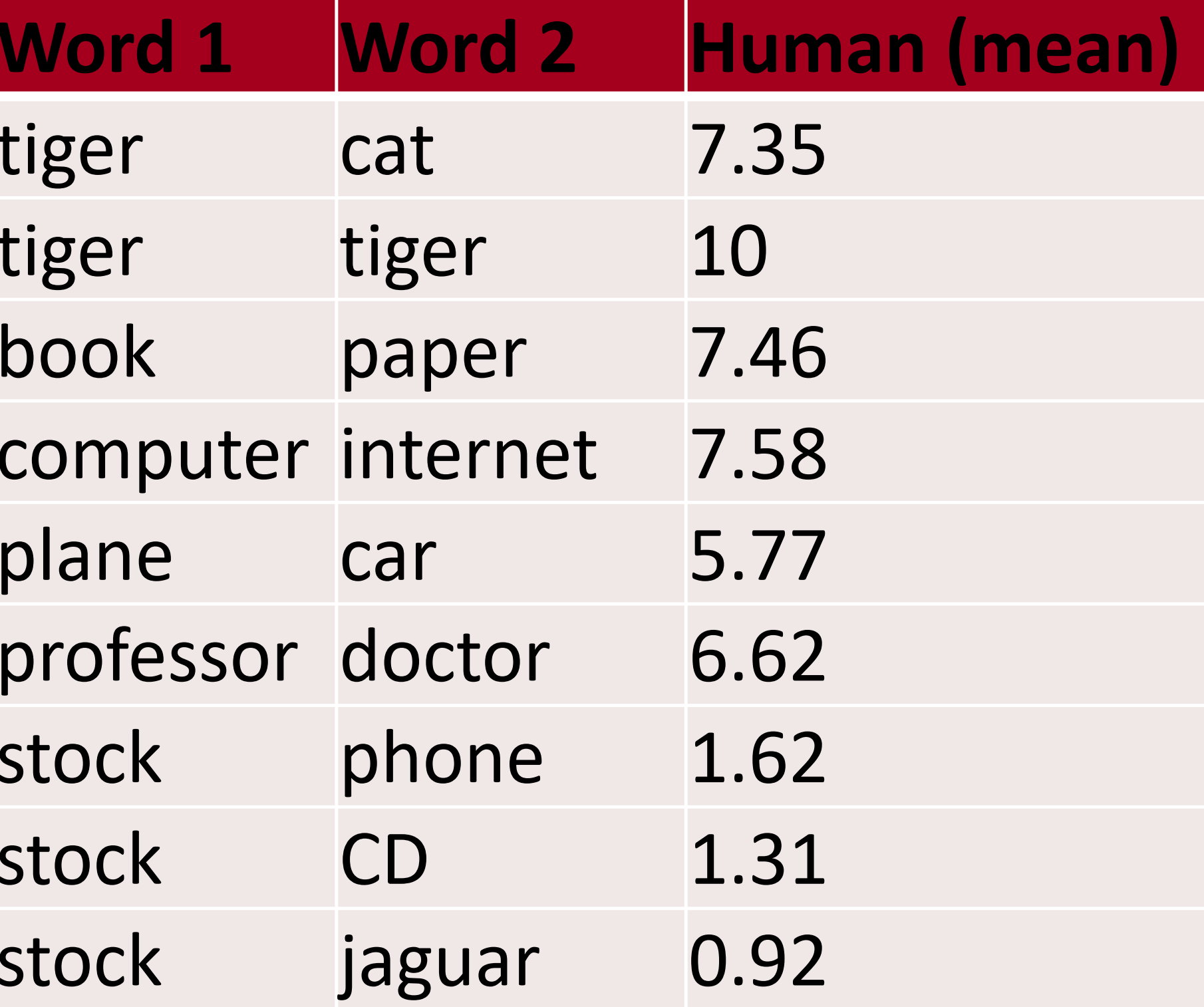
- 词向量距离和人类评判关系
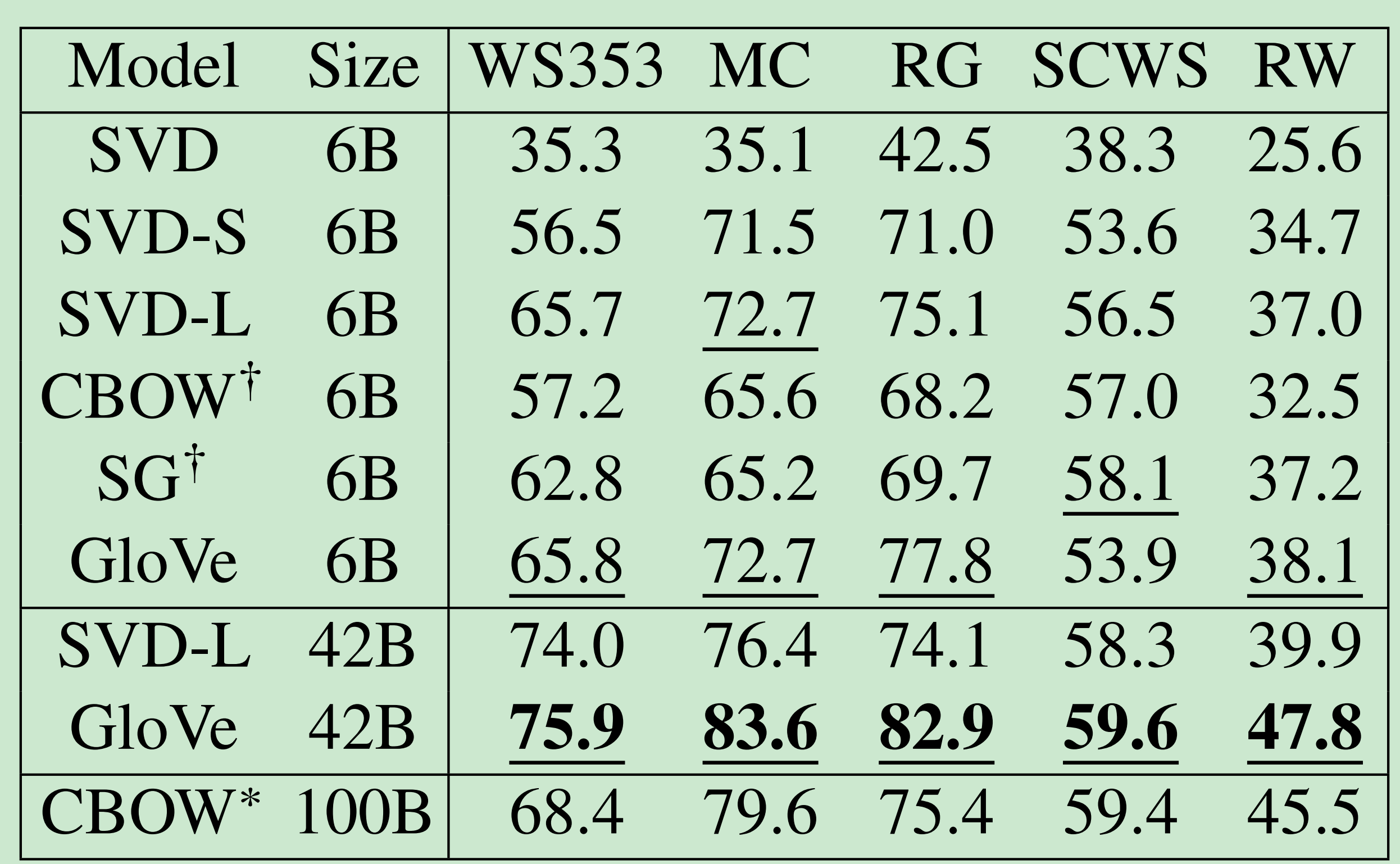
外在词向量估计
- 所有子序列任务在一类。
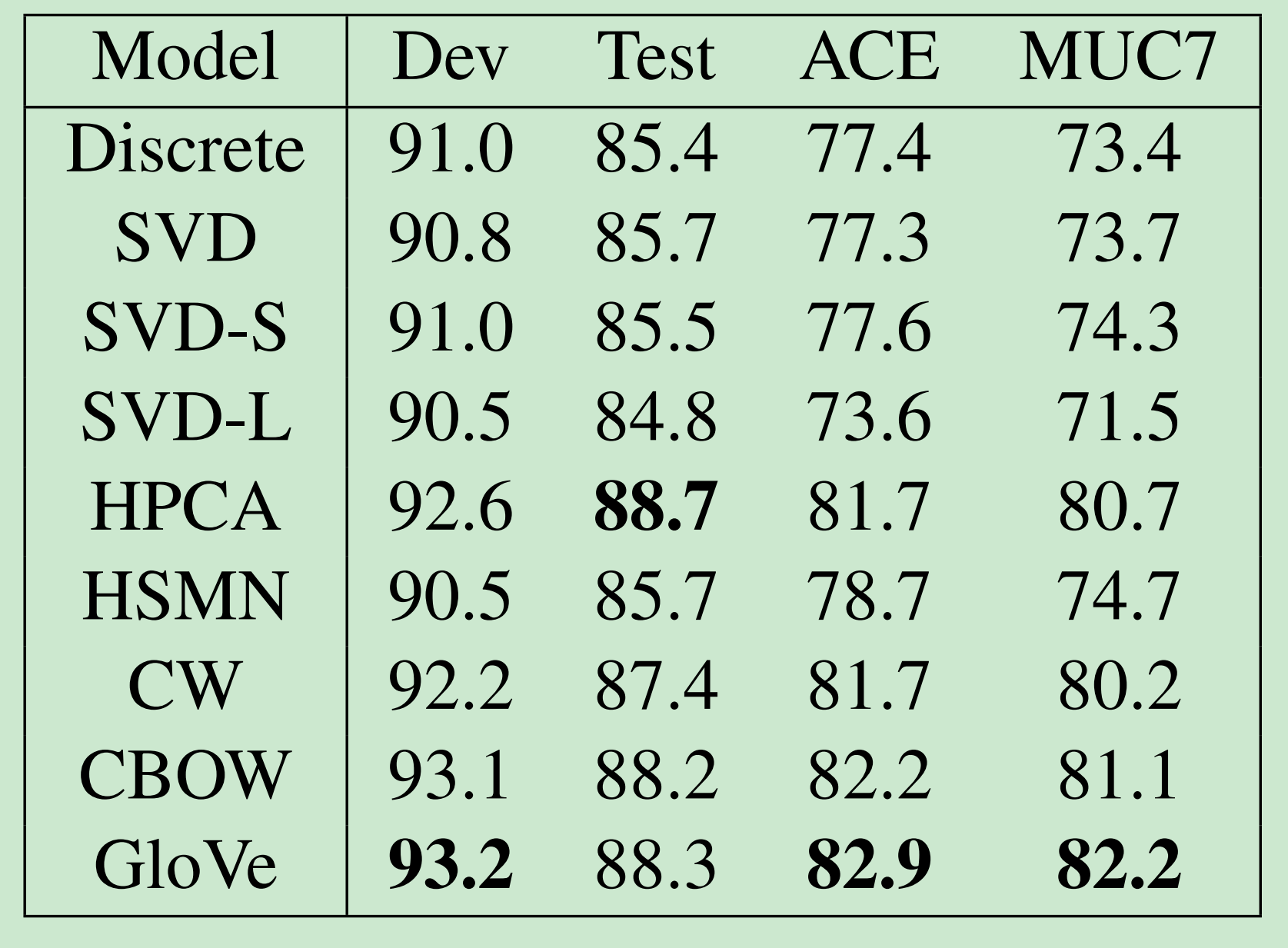
- 一个好的词向量有直接帮助:命名实体识别:找一个人,一个组织,或地点
6. 词义和消歧
Linear Algebraic Structure of Word Senses, with Applications to Polysemy—— TACL2018
一个多义词的词向量等于其各个意思的词向量的加权和。
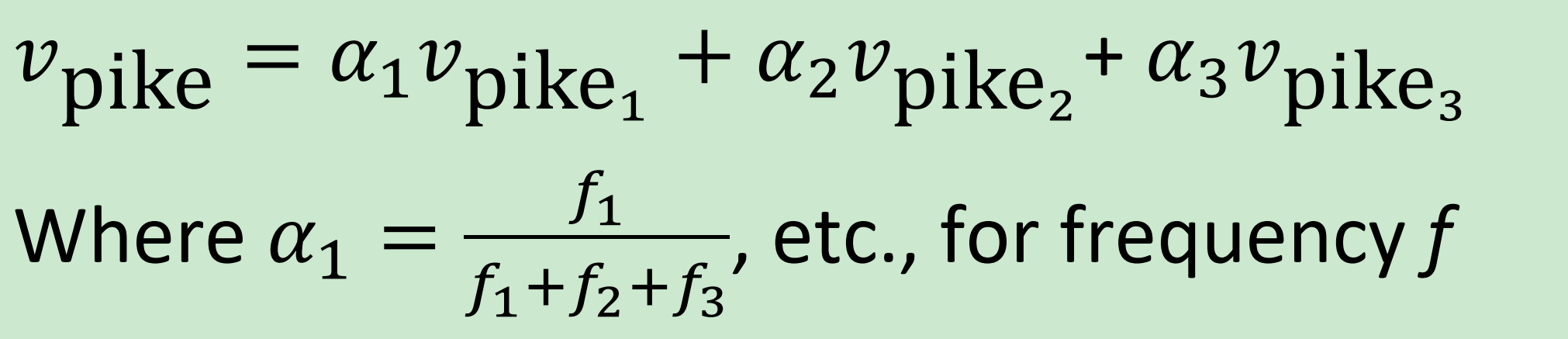
待续….
参考
[1] cs224n-2019-notes02-wordvecs2
[2] cs224n-2020-lecture02-wordvecs2
[3] 2019版CS224N中文笔记(2)词向量的计算与评价
[4] 全局向量的词嵌入
 wechat
wechat alipay
alipay



